| Overview | Package | Class | Use | Tree | Deprecated | Index | Help |
|
|
|||||||||
| PREV NEXT | FRAMES NO FRAMES | |||||||||
See:
Description
| Algorithms | |
|---|---|
| de.lmu.ifi.dbs.elki.algorithm | Algorithms suitable as a task for the KDDTask main routine. |
| de.lmu.ifi.dbs.elki.algorithm.clustering | Clustering algorithms
Clustering algorithms are supposed to implement the Algorithm-Interface. |
| de.lmu.ifi.dbs.elki.algorithm.clustering.correlation | Correlation clustering algorithms |
| de.lmu.ifi.dbs.elki.algorithm.clustering.correlation.cash | Helper classes for the CASH algorithm. |
| de.lmu.ifi.dbs.elki.algorithm.clustering.subspace | Axis-parallel subspace clustering algorithms The clustering algorithms in this package are instances of both, projected clustering algorithms or subspace clustering algorithms according to the classical but somewhat obsolete classification schema of clustering algorithms for axis-parallel subspaces. |
| de.lmu.ifi.dbs.elki.algorithm.clustering.subspace.clique | Helper classes for the CLIQUE algorithm. |
| de.lmu.ifi.dbs.elki.algorithm.clustering.trivial | Trivial clustering algorithms: all in one, no clusters, label clusterings These methods are mostly useful for providing a reference result in evaluation. |
| de.lmu.ifi.dbs.elki.algorithm.outlier | Outlier detection algorithms |
| de.lmu.ifi.dbs.elki.algorithm.outlier.meta | Meta outlier detection algorithms: external scores, score rescaling. |
| de.lmu.ifi.dbs.elki.algorithm.outlier.spatial | Spatial outlier detection algorithms |
| de.lmu.ifi.dbs.elki.algorithm.outlier.spatial.neighborhood | Spatial outlier neighborhood classes |
| de.lmu.ifi.dbs.elki.algorithm.outlier.spatial.neighborhood.weighted | Weighted Neighborhood definitions. |
| de.lmu.ifi.dbs.elki.algorithm.outlier.trivial | Trivial outlier detection algorithms: no outliers, all outliers, label outliers. |
| de.lmu.ifi.dbs.elki.algorithm.statistics | Statistical analysis algorithms The algorithms in this package perform statistical analysis of the data (e.g. compute distributions, distance distributions etc.) |
| Datatypes and Distance Functions | |
|---|---|
| de.lmu.ifi.dbs.elki.data | Basic classes for different data types, database object types and label types. |
| de.lmu.ifi.dbs.elki.data.images | Package for processing image data (e.g. compute color histograms) |
| de.lmu.ifi.dbs.elki.data.model | Cluster models classes for various algorithms. |
| de.lmu.ifi.dbs.elki.data.spatial | Spatial data types - interfaces and utilities. |
| de.lmu.ifi.dbs.elki.data.synthetic | Generators for synthetic data sets |
| de.lmu.ifi.dbs.elki.data.synthetic.bymodel | Generator using a distribution model specified in an XML configuration file. |
| de.lmu.ifi.dbs.elki.data.synthetic.bymodel.distribution | Data generators used by the model-based generator. |
| de.lmu.ifi.dbs.elki.data.type | Data type information, also used for type restrictions. |
| de.lmu.ifi.dbs.elki.distance | Distance values,
distance functions and
similarity functions. |
| de.lmu.ifi.dbs.elki.distance.distancefunction | Distance functions for use within ELKI. |
| de.lmu.ifi.dbs.elki.distance.distancefunction.adapter | Distance functions deriving distances from e.g. similarity measures |
| de.lmu.ifi.dbs.elki.distance.distancefunction.colorhistogram | Distance functions using correlations. |
| de.lmu.ifi.dbs.elki.distance.distancefunction.correlation | Distance functions using correlations. |
| de.lmu.ifi.dbs.elki.distance.distancefunction.external | Distance functions using external data sources. |
| de.lmu.ifi.dbs.elki.distance.distancefunction.geo | Geographic (earth) distance functions. |
| de.lmu.ifi.dbs.elki.distance.distancefunction.subspace | Distance functions based on subspaces. |
| de.lmu.ifi.dbs.elki.distance.distancefunction.timeseries | Distance functions designed for time series. |
| de.lmu.ifi.dbs.elki.distance.distancevalue | Distance values, i.e. object storing an actual distance value along with comparison functions and value parsers. |
| de.lmu.ifi.dbs.elki.distance.similarityfunction | Similarity functions. |
| de.lmu.ifi.dbs.elki.distance.similarityfunction.kernel | Kernel functions. |
| Evaluation | |
|---|---|
| de.lmu.ifi.dbs.elki.evaluation | Functionality for the evaluation of algorithms. |
| de.lmu.ifi.dbs.elki.evaluation.histogram | Functionality for the evaluation of algorithms using histograms. |
| de.lmu.ifi.dbs.elki.evaluation.index | Simple index evaluation methods |
| de.lmu.ifi.dbs.elki.evaluation.outlier | Evaluate an outlier score using a misclassification based cost model. |
| de.lmu.ifi.dbs.elki.evaluation.paircounting | Evaluation of clustering results via pair counting. |
| de.lmu.ifi.dbs.elki.evaluation.paircounting.generator | Pair generation for pair counting evaluation. |
| de.lmu.ifi.dbs.elki.evaluation.roc | Evaluation of rankings using ROC AUC (Receiver Operation Characteristics - Area Under Curve) |
| de.lmu.ifi.dbs.elki.evaluation.similaritymatrix | Render a distance matrix to visualize a clustering-distance-combination. |
| Utilities and Miscellaneous | |
|---|---|
| de.lmu.ifi.dbs.elki | ELKI framework "Environment for Developing KDD-Applications Supported by Index-Structures"
KDDTask is the main class of the ELKI-Framework
for command-line interaction. |
| de.lmu.ifi.dbs.elki.application | Base classes for stand alone applications. |
| de.lmu.ifi.dbs.elki.application.cache | Utility applications for the persistence layer such as distance cache builders. |
| de.lmu.ifi.dbs.elki.application.internal | Internal utilities for development. |
| de.lmu.ifi.dbs.elki.application.jsmap | JavaScript based map client - server architecture. |
| de.lmu.ifi.dbs.elki.application.visualization | Visualization applications in ELKI. |
| de.lmu.ifi.dbs.elki.logging | Logging facility for controlling logging behavior of the complete framework. |
| de.lmu.ifi.dbs.elki.logging.progress | Progress status objects (for UI) |
| de.lmu.ifi.dbs.elki.math | Mathematical operations and utilities used throughout the framework. |
| de.lmu.ifi.dbs.elki.math.linearalgebra | Linear Algebra package provides classes and computational methods for operations on matrices. |
| de.lmu.ifi.dbs.elki.math.linearalgebra.fitting | Function to numerically fit a function (such as a
Gaussian distribution
to given data. |
| de.lmu.ifi.dbs.elki.math.linearalgebra.pca | Principal Component Analysis (PCA) and Eigenvector processing. |
| de.lmu.ifi.dbs.elki.math.linearalgebra.pca.weightfunctions | Weight functions used in weighted PCA via WeightedCovarianceMatrixBuilder |
| de.lmu.ifi.dbs.elki.math.spacefillingcurves | Space filling curves. |
| de.lmu.ifi.dbs.elki.math.statistics | Statistical tests and methods. |
| de.lmu.ifi.dbs.elki.properties | Property handling and main ELKI properties file. |
| de.lmu.ifi.dbs.elki.result | Result types, representation and handling |
| de.lmu.ifi.dbs.elki.result.optics | Result classes for OPTICS. |
| de.lmu.ifi.dbs.elki.result.outlier | Outlier result classes |
| de.lmu.ifi.dbs.elki.result.textwriter | Text serialization (CSV, Gnuplot, Console, ...) |
| de.lmu.ifi.dbs.elki.result.textwriter.naming | Naming schemes for clusters (for output when an algorithm doesn't generate cluster names). |
| de.lmu.ifi.dbs.elki.result.textwriter.writers | Serialization handlers for individual data types. |
| de.lmu.ifi.dbs.elki.utilities | Utility and helper classes - commonly used data structures, output formatting, exceptions, ... |
| de.lmu.ifi.dbs.elki.utilities.datastructures | Basic memory structures such as heaps and object hierarchies. |
| de.lmu.ifi.dbs.elki.utilities.datastructures.heap | Heap structures and variations such as bounded priority heaps. |
| de.lmu.ifi.dbs.elki.utilities.datastructures.hierarchy | Delegate implementation of a hierarchy. |
| de.lmu.ifi.dbs.elki.utilities.designpattern | Interfaces and implementations related to common "design patterns". |
| de.lmu.ifi.dbs.elki.utilities.documentation | Documentation utilities: Annotations for Title, Description, Reference |
| de.lmu.ifi.dbs.elki.utilities.exceptions | Exception classes and common exception messages. |
| de.lmu.ifi.dbs.elki.utilities.iterator | Various Iterator decorators and adapters. |
| de.lmu.ifi.dbs.elki.utilities.optionhandling | Parameter handling and option descriptions. |
| de.lmu.ifi.dbs.elki.utilities.optionhandling.constraints | Constraints allow to restrict possible values for parameters. |
| de.lmu.ifi.dbs.elki.utilities.optionhandling.parameterization | Configuration managers
See the de.lmu.ifi.dbs.elki.utilities.optionhandling package for documentation! |
| de.lmu.ifi.dbs.elki.utilities.optionhandling.parameters | Classes for various typed parameters. |
| de.lmu.ifi.dbs.elki.utilities.pairs | Pairs and triples utility classes. |
| de.lmu.ifi.dbs.elki.utilities.referencepoints | Package containing strategies to obtain reference points Shared code for various algorithms that use reference points. |
| de.lmu.ifi.dbs.elki.utilities.scaling | Scaling functions: linear, logarithmic, gamma, clipping, ... |
| de.lmu.ifi.dbs.elki.utilities.scaling.outlier | Scaling of Outlier scores, that require a statistical analysis of the occurring values |
| de.lmu.ifi.dbs.elki.utilities.xml | XML and XHTML utilities. |
| de.lmu.ifi.dbs.elki.workflow | Work flow packages, e.g. following the usual KDD model, closely related to CRISP-DM |
ELKI: Environment for DeveLoping KDD-Applications Supported by Index-Structures.
ELKI is a generic framework for a broad range of KDD-applications and their development. For background, contact-information, and contributors see http://www.dbs.ifi.lmu.de/research/KDD/ELKI/.
This is the documentation for version 0.4, published as:
Elke Achtert, Ahmed Hettab, Hans-Peter Kriegel, Erich Schubert, Arthur Zimek:
Spatial Outlier Detection: Data, Algorithms, Visualizations.
12th International Symposium on Spatial and Temporal Databases (SSTD), Minneapolis, MN, 2011.
The ELKI wiki has additional documentation and will continuously be updated. A Tutorial exported from the Wiki is included with this documentation and a good place to start.
To use the KDD-Framework we recommend an executable .jar-file:
elki.jar. Since release 0.3 it will by default invoke a minimalistic GUI called MiniGUI when
you call java -jar elki.jar. For command line use (for example for batch processing and scripted operation),
you can get a description of usage by calling java -cp elki.jar de.lmu.ifi.dbs.elki.application.KDDCLIApplication -h.
The MiniGUI can also serve as a utility for building command lines, as it will print the full command line to the log window.
For more information on using files and available formats
as data input see de.lmu.ifi.dbs.elki.datasource.parser. ELKI 0.4 uses
a whitespace separated vector format by default, but there also is a parser for
ARFF files included that can read most ARFF files (mixing sparse and dense vectors is currently not allowed).
An extensive list of parameters can be browsed sorted by class or sorted by option ID.
Some examples of completely parameterized calls for different algorithms are described at example calls.
A list of related publications, giving details on many implemented algorithms, can be found in the class article references list.
The database connection manages reading of input files or databases and provides a
Database-Object - including index structures - as a virtual database to the KDDTask.
The KDDTask applies a specified algorithm on this database and collects the result from the algorithm.
Finally, KDDTask hands on the obtained result to a ResultHandler.
The default-handler is ResultWriter, writing the result to STDOUT or,
if specified, into a file.
The database and indexing layer is a key component of ELKI.
This is not just a storage for double[], as with many other frameworks.
It can store various types of objects, and the integrated index structures provide access to fast
distance,
similarity,
kNN,
RkNN and
range query methods
for a variety of distance functions.
The standard flow for initializing a database is as depicted here:
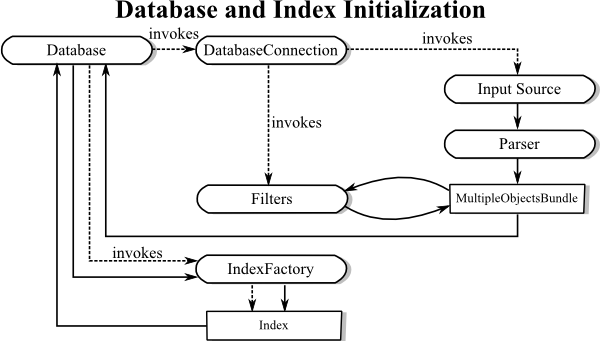
The standard stream-based data sources such as
FileBasedDatabaseConnection
will open the stream, feed the contents through a
Parser to obtain an initial
MultipleObjectsBundle. This is
a temporary container for the data, which can then be modified by arbitrary
ObjectFilters.
In the end, the
MultipleObjectsBundle
is bulk-inserted into a Database, which will then
invoke its IndexFactorys to add
Index instances to the appropriate relations.
When a request for a
distance,
similarity,
kNN,
RkNN or
range query is received by the database,
it queries all indexes if they have support for this query. If so, an optimized query is returned,
otherwise a linear scan query can be returned unless
DatabaseQuery.HINT_OPTIMIZED_ONLY
was given.
For this optimization to work, you should be using the proper APIs of the
Database interface or
QueryUtil helper where possible, instead of
initializing low level classes such as an explicit linear scan query.
For efficiency, try to instantiate the query only once per algorithm run, and avoid running the optimization step for every object.
A good place to get started is to have a look at some of the existing algorithms,
and see how they are implemented.
For example the DummyAlgorithm
while it does not produce any result, will teach you how to perform
k-nearest-neighbor queries properly. It does however have a hard dependency on the
Euclidean distance and the datatypes supported by it. In order to support arbitrary
distance functions, extend the class
AbstractDistanceBasedAlgorithm
instead. This is another simple example, this time for obtaining a class parameter.
Visit the ELKI Wiki, which has a growing amount of documentation. You are also welcome to contribute, of course!
ELKI is designed for command-line, GUI and Java operation. For command-line and GUI, an extensive help functionality is provided along with input assistance. Therefore, you should also support the parameterizable API. The requirements are quite different from regular Java constructors, and cannot be expressed in terms of a Java API.
For useful error reporting and input assistance in the GUI we need to have more extensive
typing than Java uses (for example we might need numerical constraints) and we also want to be able
to report more than one error at a time. In ELKI 0.4, much of the parameterization was
refactored to static helper classes usually found as a public static class Parameterizer
and subclasses of
AbstractParameterizer.
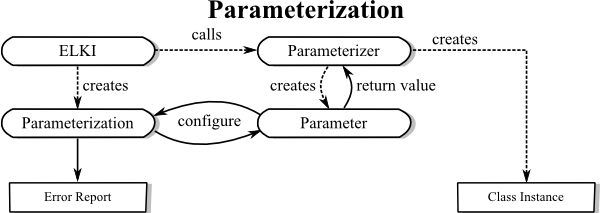
Keep the complexity of Parameterizer classes and constructors invoked by these classes low, since these may be heavily used during the parameterization step. Postpone any extensive initialization to the main algorithm invocation step!
|
|
|||||||||||
| PREV NEXT | FRAMES NO FRAMES | |||||||||||